
Qué son los cgroups y namespaces en Linux (la base de Docker, Snap y Flatpak)
Mucho antes de que Docker, Snap, Flatpak o Kubernetes se volvieran populares, el kernel de Linux ya tenía las piezas necesarias para aislar procesos y controlar recursos. Esas piezas se llaman cgroups y namespaces. En este artículo vamos a entender qué son, cómo funcionan internamente y por qué son la base real de los contenedores modernos.
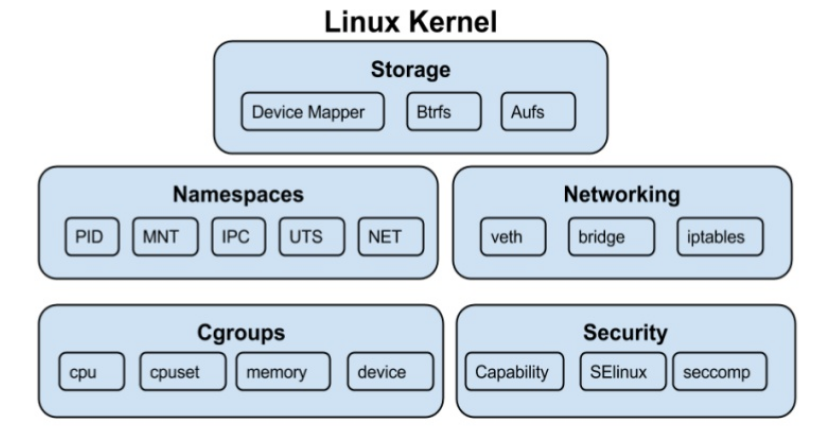
Antes de Docker: el problema que Linux necesitaba resolver
Desde siempre, Linux ejecuta múltiples procesos al mismo tiempo. Pero durante años, todos compartían el mismo sistema: mismos usuarios visibles, mismos procesos, mismo acceso a recursos.
El desafío era claro: ¿cómo aislar procesos entre sí y limitar cuánto pueden consumir? No por seguridad únicamente, sino también por estabilidad, rendimiento y control.
La respuesta del kernel llegó en dos partes bien diferenciadas:
- Namespaces: aislamiento (qué puede ver un proceso).
- Control Groups (cgroups): control de recursos (cuánto puede usar).
Namespaces: cuando cada proceso vive en su propio “mundo”
Un namespace es un mecanismo del kernel que permite que un proceso vea una versión limitada o independiente de algún recurso del sistema.
Desde el punto de vista del proceso, ese mundo es el único que existe. Desde el punto de vista del kernel, todo sigue conviviendo en el mismo sistema.
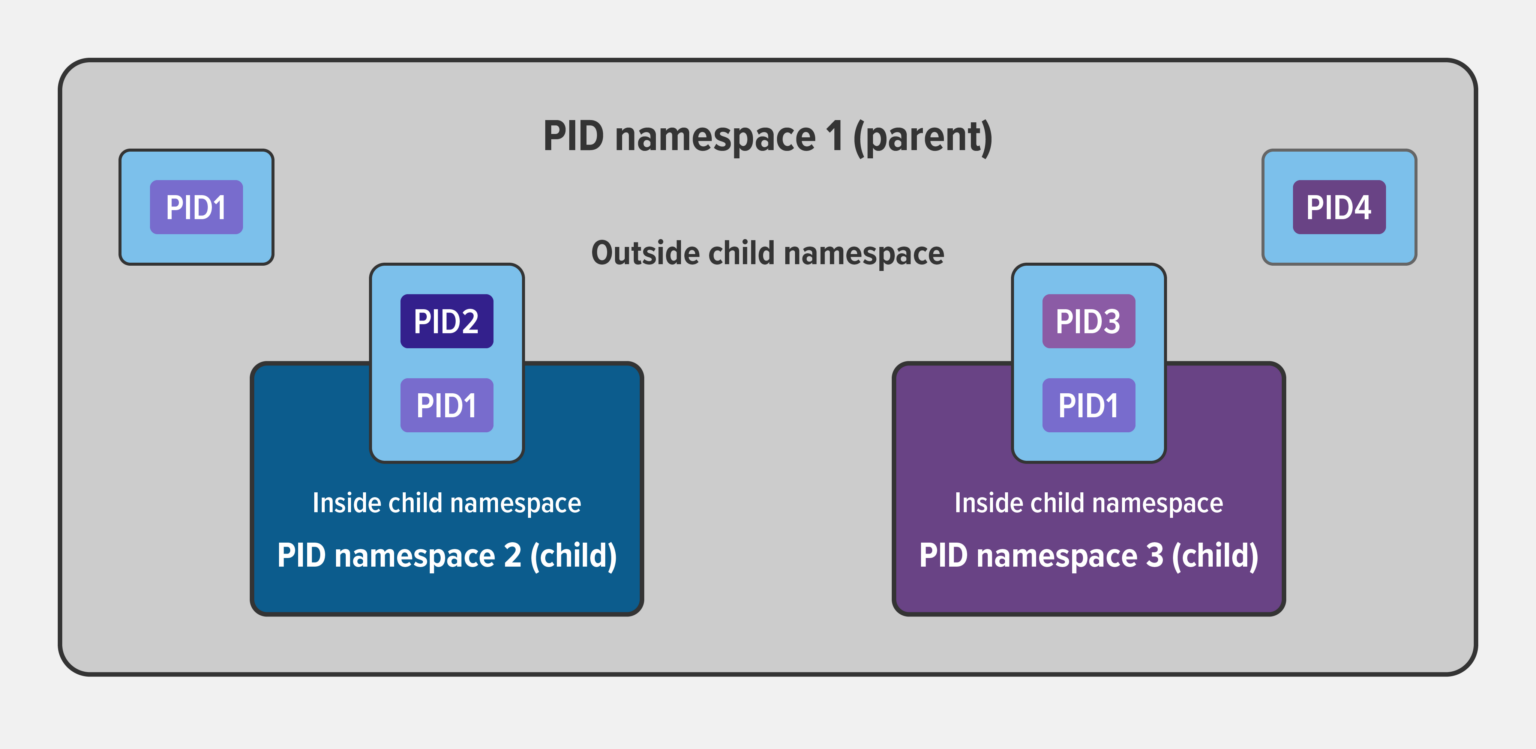
Tipos de namespaces más importantes
- PID namespace: aísla los IDs de procesos (un proceso puede verse como PID 1).
- Mount namespace: aísla puntos de montaje y sistemas de archivos.
- Network namespace: interfaces de red, IPs, rutas y puertos propios.
- User namespace: mapea usuarios y permisos (root “falso”).
- UTS namespace: hostname y dominio.
- IPC namespace: colas de mensajes y memoria compartida.
Idea clave: los namespaces no limitan recursos. Solo definen qué puede ver un proceso.
Cgroups: controlando cuánto puede consumir un proceso
Los cgroups (control groups) permiten agrupar procesos y limitar, priorizar o medir el uso de recursos del sistema.
A diferencia de los namespaces, los cgroups no ocultan nada: actúan como un regulador.
Recursos que pueden controlarse
- CPU: porcentaje, cuotas, prioridades.
- Memoria RAM: límites duros y blandos, swap.
- I/O: acceso a disco y prioridades.
- PIDs: cantidad máxima de procesos.
Gracias a los cgroups, un proceso no puede “comerse” toda la máquina, incluso si se comporta mal.
# Ejemplo ilustrativo: ver cgroups activos
$ mount | grep cgroup
# Ver cgroups de un proceso
$ cat /proc/1234/cgroupNamespaces + cgroups: la combinación poderosa
Por separado, namespaces y cgroups son útiles. Juntos, permiten algo revolucionario:
- Procesos que creen ser los únicos en el sistema.
- Recursos estrictamente controlados.
- Aislamiento sin virtualizar hardware.
Eso es, en esencia, un contenedor. No hay magia, no hay emulación, no hay “mini sistema operativo”. Solo kernel de Linux haciendo bien su trabajo.
Docker, Flatpak, Snap y Kubernetes: distintos usos, misma base
Aunque se usan en contextos diferentes, todas estas tecnologías descansan sobre los mismos mecanismos del kernel:
- Docker: contenedores para aplicaciones y servicios.
- Flatpak: aislamiento de aplicaciones de escritorio.
- Snap: aislamiento de aplicaciones y servicios.
- Kubernetes: orquestación de contenedores a gran escala.
La diferencia no está en el kernel, sino en las capas de usuariospace: herramientas, formatos, políticas y automatización.
¿Son seguros los contenedores?
Los contenedores no son máquinas virtuales. Comparten el mismo kernel, lo que implica ventajas enormes de rendimiento, pero también desafíos de seguridad.
Por eso entran en juego mecanismos adicionales:
- SELinux / AppArmor
- Seccomp
- User namespaces
- Capacidades de Linux
Bien configurados, los contenedores son seguros. Mal configurados, pueden ser una puerta abierta.
Enlaces útiles
- Documentación oficial de cgroups (kernel.org)
- Namespaces — man7.org
- Docker: visión general
- Proyecto Flatpak
- Proyecto Snap
Conclusión
Cgroups y namespaces no son una moda ni una invención reciente: son decisiones de diseño profundas del kernel de Linux. Gracias a ellos, hoy podemos ejecutar aplicaciones aisladas, controlar recursos y construir infraestructuras modernas sin abandonar la eficiencia del sistema base.
Entender estos conceptos cambia por completo la forma de ver Docker, Flatpak o Kubernetes: dejan de ser “magia” y pasan a ser Linux en su máxima expresión.





