
¿Qué es el load average en Linux y cómo interpretarlo correctamente?
Si alguna vez ejecutaste top, uptime o htop, seguramente viste tres números misteriosos llamados load average. Mucha gente piensa que representan el uso de CPU… pero no es así. En este artículo te explico qué significan realmente, cómo interpretarlos y por qué son clave para entender el rendimiento de un sistema Linux.
¿Qué es el load average?
El load average es una métrica que indica cuántos procesos están usando o esperando usar la CPU.
Es importante entender que no mide porcentaje de uso, sino cantidad de procesos en cola o ejecución.
Se puede ver fácilmente con:
$ uptime
18:42:10 up 2:10, 1 user, load average: 0.52, 0.60, 0.75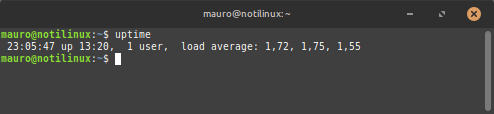
Estos tres valores representan el promedio de carga en:
- 1 minuto
- 5 minutos
- 15 minutos
Idea clave: el load average indica cuántos procesos están compitiendo por CPU, no cuánto se está usando.
Cómo interpretar los valores correctamente
La clave está en compararlo con la cantidad de CPUs (o cores) del sistema.
Podés ver cuántos cores tenés con:
$ nprocRegla general
- Load = número de CPUs → sistema al límite
- Load menor → sistema relajado
- Load mayor → hay procesos esperando
Ejemplos
CPU de 1 núcleo:
- Load 0.5 → todo bien
- Load 1.0 → al máximo
- Load 2.0 → procesos en cola
CPU de 4 núcleos:
- Load 2.0 → bien
- Load 4.0 → límite
- Load 8.0 → saturado
Algo clave: no solo CPU
Aunque su nombre sugiere CPU, el load average también incluye procesos en estado:
- R (running) → ejecutándose
- D (uninterruptible sleep) → esperando I/O (disco, red, etc.)
Esto significa que un sistema puede tener:
- CPU baja
- pero load average alto
¿Por qué? Porque hay procesos esperando disco o red.
Ejemplo típico: un disco lento puede disparar el load sin que la CPU esté ocupada.
Cómo verlo en tiempo real
Con top
$ topEn la parte superior vas a ver:
load average: 1.20, 0.95, 0.80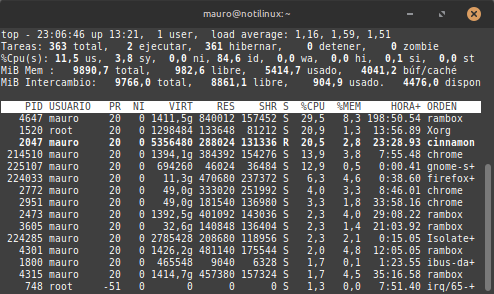
Con htop
$ htopMás visual, ideal para detectar procesos problemáticos.
Con uptime
$ uptimeLa forma más rápida de verlo.
Cómo interpretar tendencias
Los tres valores sirven para detectar tendencias:
- 1 min > 5 min > 15 min → carga en aumento
- 1 min < 5 min < 15 min → carga bajando
- Valores similares → sistema estable
Esto es clave en servidores para detectar problemas antes de que exploten.
Errores comunes al interpretar el load
- ❌ Pensar que es porcentaje de CPU
- ❌ Ignorar la cantidad de cores
- ❌ No considerar I/O
- ❌ Alarmarse por números sin contexto
El load average no es bueno ni malo por sí solo, todo depende del hardware y del tipo de carga.
Casos reales
Servidor web saturado
Load alto + CPU alta → falta de capacidad de procesamiento.
Disco lento
Load alto + CPU baja → cuello de botella en I/O.
Proceso bloqueado
Load sube constantemente → procesos esperando recursos.
Conclusión
El load average es una de las métricas más útiles para entender el estado de un sistema Linux, pero también una de las más mal interpretadas.
No mide uso de CPU, sino cuántos procesos están compitiendo por recursos. Interpretarlo correctamente implica tener en cuenta los cores, el tipo de carga y el comportamiento del sistema en el tiempo.
Dominar esta métrica te permite detectar problemas antes de que se conviertan en caídas, algo fundamental en servidores, entornos productivos y sistemas críticos.





